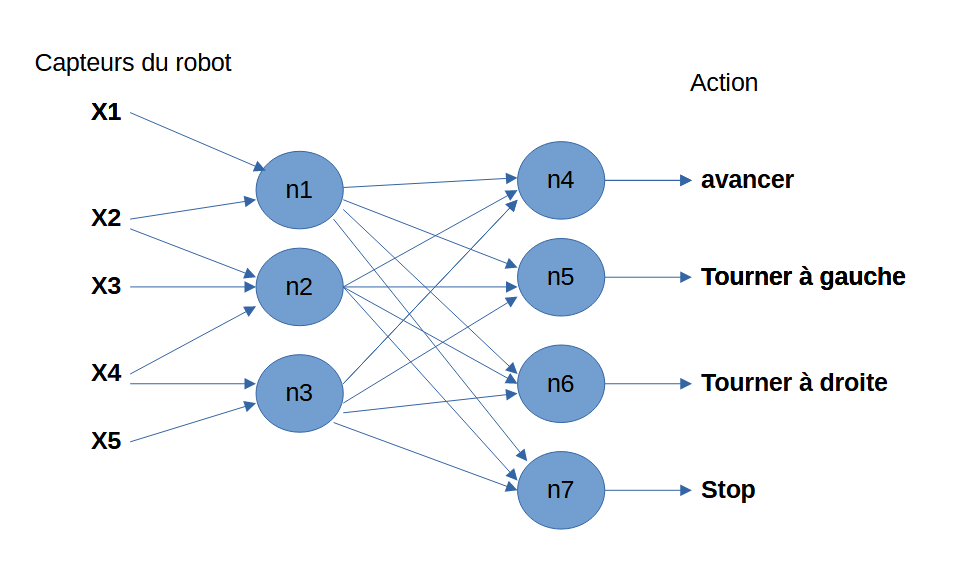
Dans cet article nous allons apprendre au robot MR25 à éviter les obstacles en utilisant un réseau de neurones. Nous allons coder un réseau à 2 couches, une seule couche (le perceptron) suffit quand le problème est linéairement séparable, c’est-à-dire qu’on peut tracer une ligne droite entre les cas « oui » et les cas « non ».
Éviter un obstacle unique devant soi, c’est ce cas. Simple, rapide, mais très limité. Deux couches de neurones permet de résoudre des problèmes avec des frontières courbes ou des zones multiples. C’est exactement notre cas : il faut distinguer 4 situations (libre, gauche, droite, obstacle) qui ne sont pas séparables par une seule ligne dans l’espace des 5 capteurs.
La couche 1 construit des « concepts intermédiaires » (obstacle gauche, obstacle devant, obstacle droite), et la couche 2 combine ces concepts pour décider (action).
Le réseau apprend grâce à la rétropropagation du gradient, puis pilote le robot en temps réel en transformant les mesures des capteurs en actions de navigation et d’évitement d’obstacles. La rétropropagation du gradient (backpropagation en anglais) est l’algorithme qui permet à un réseau de neurones d’apprendre de ses erreur, on commence par corriger la couche de sortie, puis on remonte vers la couche 1.
Le gradient indique dans quelle direction modifier les poids pour diminuer l’erreur le plus rapidement. Le gradient indique la pente. Le réseau suit la pente descendante pour atteindre le minimum d’erreur.
#!/usr/bin/python3
import MR25
import time
import math
# =============================================================================
# MR25 — Réseau de neurones à deux couches
# =============================================================================
#
# Couche 1 : 3 neurones de perception (5 entrées → 3 sorties continues)
#
# Neurone 1 (gauche) : capteurs 1 et 2
# Neurone 2 (devant) : capteurs 2, 3 et 4
# Neurone 3 (droite) : capteurs 4 et 5
#
# Couche 2 : 4 neurones de décision (3 entrées → 4 sorties)
#
# Sortie 0 : AVANCE
# Sortie 1 : TOURNE GAUCHE
# Sortie 2 : TOURNE DROITE
# Sortie 3 : STOP
#
# =============================================================================
# -----------------------------
# Fonctions d'activation
# -----------------------------
def sigmoid(x):
"""
Fonction sigmoïde — sortie continue dans ]0, 1[.
Utilisée dans la couche 1 pour produire un 'niveau d'obstacle' graduel.
"""
return 1.0 / (1.0 + math.exp(-x))
def softmax(vec):
"""
Softmax — transforme un vecteur en distribution de probabilités.
Utilisée dans la couche 2 : la somme des 4 sorties vaut 1.
L'action choisie est celle dont la probabilité est la plus haute.
"""
e = [math.exp(v) for v in vec]
s = sum(e)
return [v / s for v in e]
# -----------------------------
# Architecture du réseau
# -----------------------------
#
# Couche 1 — poids W1[neurone][capteur] et biais B1[neurone]
#
# Chaque neurone de perception combine les capteurs de son côté.
# Valeurs initiales : chaque capteur pèse pareil, biais nul.
#
# neurone 0 (gauche) → capteurs x1, x2
# neurone 1 (devant) → capteurs x2, x3, x4 (x2 et x4 = flancs proches centre)
# neurone 2 (droite) → capteurs x4, x5
W1 = [
# x1 x2 x3 x4 x5
[0.5, 0.5, 0.0, 0.0, 0.0], # neurone 0 : gauche
[0.0, 0.33, 0.33, 0.33, 0.0], # neurone 1 : devant
[0.0, 0.0, 0.0, 0.5, 0.5], # neurone 2 : droite
]
B1 = [0.0, 0.0, 0.0]
# Couche 2 — poids W2[action][neurone] et biais B2[action]
#
# action 0 (AVANCE) → récompenser l'ABSENCE d'obstacle
# action 1 (TOURNE GAUCHE) → obstacle à droite, pas à gauche
# action 2 (TOURNE DROITE) → obstacle à gauche, pas à droite
# action 3 (STOP) → obstacle des deux côtés
W2 = [
# n_gauche n_devant n_droite
[-0.5, -1.0, -0.5], # AVANCE : mauvais score si obstacle
[ 0.0, -0.5, 1.0], # TOURNE GAUCHE: obstacle à droite
[ 1.0, -0.5, 0.0], # TOURNE DROITE: obstacle à gauche
[ 0.5, 1.0, 0.5], # STOP : obstacles partout
]
B2 = [0.0, 0.0, 0.0, 0.0]
# Taux d'apprentissage
eta = 0.1
# -----------------------------
# Jeu d'entraînement
# -----------------------------
#
# Entrées : [x1, x2, x3, x4, x5] normalisées dans [0, 1]
# 0 = obstacle très proche 1 = voie libre
#
# Cibles : indice de l'action correcte
# 0 = AVANCE 1 = TOURNE GAUCHE 2 = TOURNE DROITE 3 = STOP
#
# Répartition des capteurs sur le MR25 (vue de dessus) :
#
# [1] [2] [3] [4] [5]
# \ | (avant) | /
# gauche droite
training_data = [
# Voie complètement libre → AVANCE
([1.0, 1.0, 1.0, 1.0, 1.0], 0),
# Obstacle devant uniquement → STOP (pas d'info sur quel côté éviter)
([0.9, 0.9, 0.1, 0.9, 0.9], 3),
# Obstacle à gauche (capteurs 1-2 faibles) → TOURNE DROITE
([0.1, 0.2, 0.8, 0.9, 0.9], 2),
([0.2, 0.1, 1.0, 1.0, 1.0], 2),
# Obstacle à droite (capteurs 4-5 faibles) → TOURNE GAUCHE
([0.9, 0.9, 0.8, 0.2, 0.1], 1),
([1.0, 1.0, 1.0, 0.1, 0.2], 1),
# Obstacle sur toute la largeur → STOP
([0.1, 0.1, 0.1, 0.1, 0.1], 3),
([0.2, 0.3, 0.2, 0.3, 0.2], 3),
# Obstacle léger devant-gauche, droite libre → TOURNE DROITE
([0.3, 0.4, 0.4, 0.8, 0.9], 2),
# Obstacle léger devant-droite, gauche libre → TOURNE GAUCHE
([0.9, 0.8, 0.4, 0.4, 0.3], 1),
]
# Noms des actions (pour les affichages)
ACTIONS = ["AVANCE", "TOURNE GAUCHE", "TOURNE DROITE", "STOP"]
# -----------------------------
# Propagation avant (forward pass)
# -----------------------------
def forward(inputs):
"""
Calcule la sortie complète du réseau pour un vecteur d'entrées.
Retourne :
h — sorties de la couche 1 (3 valeurs sigmoïdes)
probs — distribution softmax de la couche 2 (4 probabilités)
action — indice de l'action ayant la probabilité la plus haute
"""
# --- Couche 1 : neurones de perception ---
h = []
for n in range(3):
z = sum(W1[n][i] * inputs[i] for i in range(5)) + B1[n]
h.append(sigmoid(z))
# --- Couche 2 : neurones de décision ---
logits = []
for a in range(4):
z = sum(W2[a][n] * h[n] for n in range(3)) + B2[a]
logits.append(z)
probs = softmax(logits)
action = probs.index(max(probs))
return h, probs, action
# -----------------------------
# Mise à jour des poids (rétropropagation simplifiée)
# -----------------------------
#
# On utilise une règle delta adaptée au softmax + entropie croisée :
# delta_couche2[a] = probs[a] - (1 si a == cible, sinon 0)
#
# Pour la couche 1, on rétropropage le gradient à travers la sigmoïde :
# delta_couche1[n] = sigmoid'(h[n]) * somme_a(W2[a][n] * delta_c2[a])
# avec sigmoid'(h) = h * (1 - h)
def train_step(inputs, target, h, probs):
"""
Effectue une mise à jour des poids W1, B1, W2, B2
à partir d'un exemple (inputs, target).
"""
# --- Gradient couche 2 ---
delta2 = [probs[a] - (1.0 if a == target else 0.0) for a in range(4)]
# --- Mise à jour W2, B2 ---
for a in range(4):
for n in range(3):
W2[a][n] -= eta * delta2[a] * h[n]
B2[a] -= eta * delta2[a]
# --- Gradient couche 1 (rétropropagation) ---
delta1 = []
for n in range(3):
grad = sum(W2[a][n] * delta2[a] for a in range(4))
delta1.append(h[n] * (1.0 - h[n]) * grad)
# --- Mise à jour W1, B1 ---
for n in range(3):
for i in range(5):
W1[n][i] -= eta * delta1[n] * inputs[i]
B1[n] -= eta * delta1[n]
# -----------------------------
# Phase d'apprentissage
# -----------------------------
print("=" * 50)
print(" APPRENTISSAGE DU RÉSEAU DE NEURONES")
print("=" * 50)
for epoch in range(500):
nb_erreurs = 0
for inputs, target in training_data:
h, probs, action = forward(inputs)
if action != target:
nb_erreurs += 1
train_step(inputs, target, h, probs)
# Affichage toutes les 50 époques
if (epoch + 1) % 50 == 0:
print(f"Époque {epoch + 1:4d} — erreurs : {nb_erreurs}/{len(training_data)}")
if nb_erreurs == 0:
print(f"\nConvergence atteinte à l'époque {epoch + 1}")
break
print("\nPoids finaux — couche 1 (perception) :")
for n, nom in enumerate(["Gauche", "Devant", "Droite"]):
print(f" Neurone {nom} : w={[f'{v:.3f}' for v in W1[n]]} b={B1[n]:.3f}")
print("\nPoids finaux — couche 2 (décision) :")
for a, nom in enumerate(ACTIONS):
print(f" {nom:15s} : w={[f'{v:.3f}' for v in W2[a]]} b={B2[a]:.3f}")
# Vérification finale sur le jeu d'entraînement
print("\nVérification sur les données d'entraînement :")
for inputs, target in training_data:
_, probs, action = forward(inputs)
statut = "✓" if action == target else "✗"
print(f" {statut} capteurs={inputs} attendu={ACTIONS[target]:15s} obtenu={ACTIONS[action]}")
print("\nDémarrage du robot dans 5 secondes…")
time.sleep(5)
# -----------------------------
# Pilotage en temps réel
# -----------------------------
SEUIL_MAX = 80.0 # mm — distance au-delà de laquelle la voie est considérée libre
print("\n" + "=" * 50)
print(" PILOTAGE EN COURS (Ctrl+C pour stopper)")
print("=" * 50)
try:
while True:
# --- Lecture et normalisation des 5 capteurs ---
raw = [MR25.proxSensor(i) for i in range(1, 6)]
inputs = [min(v, SEUIL_MAX) / SEUIL_MAX for v in raw]
# --- Inférence ---
h, probs, action = forward(inputs)
# --- Affichage diagnostique ---
obstacle = ["⬛" if v < 0.5 else "⬜" for v in inputs]
print(
f"Capteurs {''.join(obstacle)} "
f"G={h[0]:.2f} D={h[1]:.2f} Dr={h[2]:.2f} "
f"→ {ACTIONS[action]}"
)
# --- Commande moteur ---
if action == 0:
MR25.forward(40)
elif action == 1:
MR25.turnLeft(30)
elif action == 2:
MR25.turnRight(30)
else:
MR25.stop()
time.sleep(0.1) # 10 Hz
except KeyboardInterrupt:
MR25.stop()
print("\nArrêt propre.")
# end of file